Dude, Where’s My Data?

Q: Where do you look for scientific data?
A: In scientific papers, stoopid!
Sadly, of course, anyone who’s read a scientific paper will know that this isn’t true. Papers actually contain very little raw data, and mostly consist of analysis of the data and discussion of conclusions that can be drawn from the data. That’s OK up to a point, but what if you’re sceptical about the analysis and want to have a shot at doing it yourself? What if you’ve got a nifty idea about using the same data to address a completely different question? The chances are that you’ll have to look further than the paper itself, and, especially if the paper’s old, you may well find that the raw data no longer exist.
The conciseness of the modern scientific paper has presumably arisen historically because a) papers used to be constrained by the space available in old-fashioned printed formats, b) lots of data can obscure the central message of a paper, and c) we didn’t used to have much data anyway. These days we have online journals with unlimited pages, the possibility of substantial supplementary information files, and hyperlinks to robust data repositories, so surely, even with our terabyte-sized datasets, we don’t have to worry anymore?
Well, some fields are pretty good at this – it’s hard to imagine a paper reporting new genomic sequence or a new protein structure not having an accession number that will lead you directly to an online repository (GenBank, PDB, for example) containing the full sequence or coordinates (though I concede that in each of these instances, the sequence/coordinates already represent a level of interpretation of the raw data, which in turn will be less accessible). So although most of the ~300 GenBank entries that carry my name will never be of use to anyone, at least my unborn grandchildren will be able to look at them in puzzled indifference. However, it seems that there are many areas of science where we run the risk of losing most of the data upon which the literature is based.
In a Perspective just published in PLOS Biology, Bryan Drew and colleagues directly test their ability to retrieve the data that underlie one field of endeavour, and find a “massive failure” that they attribute to cultural problems. This piece, “Lost Branches in the Tree of Life”, tackles the specific problem of the “phylogenetic trees” that show the evolutionary relationship between different species (see a previous Biologue post of mine for more about phylogenetic trees).
Constructing trees of life involves the collection of data from organisms that are often rare or exotically located – these are very special data. The resulting publications always present trees as figure panels, but vary as to whether the topological and branch-length properties of the trees, and the sequence alignments themselves, are made available to readers by deposition in a database (e.g. Dryad, TreeBASE). Access to the alignments would allow you to check the original paper’s findings, add your own species, or combine data from different papers to make your own super-tree…
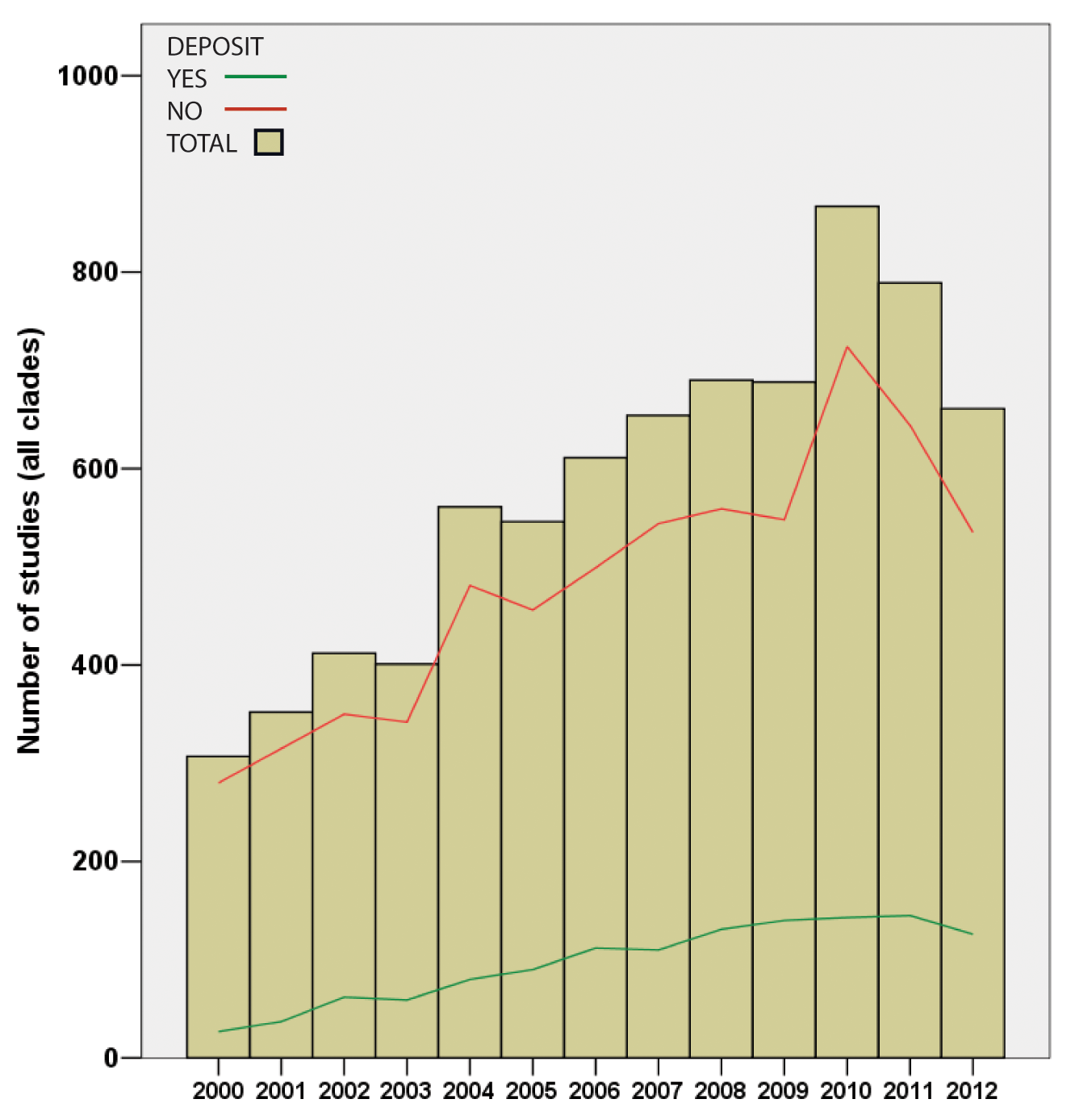
…and it was while making their own super-tree of life comprising nearly two million species that Drew and co-authors noted that of the 7500 papers they studied, data had been deposited for only one-sixth and were available on request from the original authors in a further one-sixth, leaving two-thirds of trees only available as figure panels in the original paper. Lest you assume that the authors were looking back into the Dark Ages before the internet, all papers examined were from the fully digital years 2000-2012. This represents a potentially irretrievable loss of the bulk of the data on which this field rests, and there’s little sign of any improvement.
In a separate Perspective, “Spatially Explicit Data Stewardship and Ethical Challenges in Science”, also just published in PLOS Biology, Joel Hartter and co-authors look at a broader issue of data management, stewardship and sharing across many types of scientific data. They note cultural differences between fields, especially regarding the basic tendency either to share or to guard data. They cover spatially explicit geographical and sociological datasets, and raise the peculiar ethical problems that can arise from the conflict between openness and confidentiality in these fields. These issues are particularly heightened when considering the potentially socially intrusive nature of crowd-sourced and geospatial data. The authors propose a series of measures intended to foster openness while protecting the diverse interests at stake.
Back in June we published a third plea for data availability, from Dani Zamir, “Where have all the crop phenotypes gone?” He also lamented the likely irreversible loss of huge bodies of valuable data generated by large-scale plant breeding programmes devised to map the genetic determinants of desirable (or undesirable) crop traits, and asked “how can we bring about a phenotype sharing revolution?”
In each case, across these disparate fields, we see very low levels of data availability, and it may be that some (many?) fields perform even worse than the dismaying one-sixth that Drew and colleagues saw in phylogenetics. In each instance, the Perspective authors identify the problems as largely cultural, and propose ways forward, asking journals and funding agencies to insist on deposition of valuable and sometimes irreplaceable data.
And it’s clear that journals are indeed spectacularly well-placed to police and incentivise the deposition, tracking, accessibility, and permanence of data associated with the papers that they publish. At the point of acceptance we have the authors over a barrel, and are in a great position to mandate deposition of all data for every paper. And why stop at the data? What about mathematical models and code used for the analysis, both of which are important resources and arguably a formal requirement for reproducibility?
In our guidelines we do insist on depositions (“All appropriate datasets, images, and information should be deposited in public resources.”), and we do try to ensure that the more obvious data are deposited, but I suspect that some slip under the radar. For these we rely on the authors recognising that data sharing is not only good for readers, but is also good for them, enhancing the longevity and (dramatic pause…) citeability of their work.
Want to read more? See other Biologue posts about Open Data and related issues by John Chodacki and Theo Bloom.
Declaration of potential conflict of interest: I’m a PLOS Biology editor and an employee of PLOS.