Why I love the H-index
The H-index – a small number with a big impact. First introduced by Jorge E. Hirsh in 2005, it is a relatively simple way to calculate and measure the impact of a scientist (Hirsch, 2005). It divides opinion. You either love it or hate it. I happen to think the H-index is a superb tool to help assess scientific impact. Of course, people are always favourable towards metrics that make them look good. So let’s get this out into the open now, my H-index is 44 (I have 44 papers with at least 44 citations) and, yes, I’m proud of it! But my love of the H-index stems from a much deeper obsession with citations.
As an impressionable young graduate student, I saw my PhD supervisor regularly check his citations. Citations to papers means that someone used your work or thought it was relevant to mention in the context of their own work. If a paper was never cited, and perhaps therefore also little read, was it worth doing the research in the first place? I still remember the excitement of the first citation I ever received and I still enjoy seeing new citations roll in.
The H index: what does it mean, how is it calculated and used?
The H-index measures the maximum number of papers N you have, all of which have at least N citations. So if you have 3 papers with at least 3 citations, but you don’t have 4 papers with at least 4 citations then your H-index is 3. Obviously, the H-index can only increase if you keep publishing papers and they are cited. But the higher your H-index gets, the harder it is to increase it.
One of the ways in which I use the H-index is when making tenure recommendations. By placing the candidate within the context of the H-indices of their departmental peers, I can judge the scientific output of the candidate within the context of the host institution. This is a useful because it can be difficult to understand what is required at different host institutions from around the world. It would be negligent to only look at H-index and so I use a range of other metrics as well, together with good old fashioned scientific judgement of their contributions from reading their application and papers.
The m value
One of those extra metrics I use was also introduced by Hirsch, and is called m (Hirsch, 2005). M measures the slope or rate of increase of the H-index over time and is, in my view, a greatly underappreciated measure. To calculate the m-value, take the researchers H-index and divide by the number of years since their first publication. This measure helps to normalise between those at the early or twilight stages of their career. As Hirsch did for physicists in the field of computational biology, I broadly categorise people according to their m value in the table below. The boundaries correspond exactly to those used by Hirsch.
| m-value – H-index/yr | Potential for Scientific Impact |
| <1.0 | Average |
| 1.0-2.0 | Above average |
| 2.0-3.0 | Excellent |
| >3.0 | Stellar |
So post-docs with an m-value of greater than three are future science superstars and highly likely to have a stratospheric rise. If you can find one, hire them immediately!
The H-trajectory
The graph below shows the growth of the H-index for three scientists – A, B and C – who respectively have an H-index of 12, 15 and 16. I call these curves a researcher’s H-trajectory.
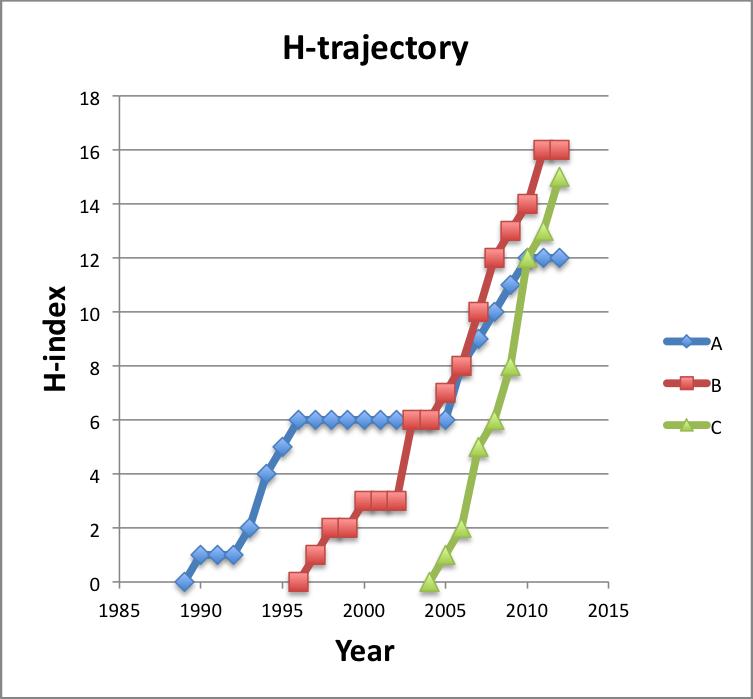
If we calculate their m-value, then we find that A has a value of 0.5, B has 0.94 and C a value of 1.67. So while each of these researchers has a similar H-index, their likelihood for future growth can be predicted based on past performance. Recently, Daniel Acuna and colleagues presented a sophisticated prediction of future H-index using a number of several features, such as number of publications and the number in top journals (Acuna et al. 2012).
As any serious citation gazer knows, the H-index has numerous potential problems. For example, researcher A who spent time in industry has fewer publications, people with names in non English alphabets or very common names can be difficult to correctly calculate, different fields have widely differing authorship, publication and citation patterns. But even considering all these problems, I believe the H-index is here to stay. My experience is that ranking scientists by H-index and m-value correlates very well with my own personal judgements about the impact of scientists that I know and indeed with the positions that those scientists hold in Universities around the world.
Alex Bateman is currently a computational biologist at the Wellcome Trust Sanger Institute where he has led the Pfam database project. On Novembert 1st, he takes up a new role as Head of Protein Sequence Resources at the EMBL-European Bioinformatics Institute (EMBL-EBI).
References
J.E. Hirsch. An index to quantify an individual’s scientific research output. Proc. Natl. Acad. Sci. 102, 16569-16572.
D.E. Acuna, S. Allesina & P. Konrad. Predicting scientific success. Nature 489, 201-202.