Quantifying Transcript Isoforms, Druggable Interactome Nodes, and ShortBRED for Metagenome Mapping: the PLOS Comp Biol December Issue

Here are some of our highlights from the last PLOS CB issue of 2015..
Network-Based Isoform Quantification with RNA-Seq Data
New sequencing technologies for transcriptome-wide profiling of RNAs have greatly promoted the interest in isoform-based functional characterizations of a cellular system. Elucidation of gene expression at the resolution of individual isoforms could lead to new molecular mechanisms, and potentially better molecular signals for phenotype predictions. Rui Kuang and colleagues examine the possibility of using protein domain-domain interactions as prior knowledge in isoform transcript quantification.
Distinctive Behaviors of Druggable Proteins in Cellular Networks
The need for well-validated targets for drug discovery is more pressing than ever, especially in cancer, in view of resistance to current therapeutics and late-stage drug failures. Bissan Al-Lazikani and colleagues analyze a large representation of the human interactome comprising almost 90,000 interactions between 13,345 proteins. The authors assess these interactions using an extensive set of topological, graphical and community parameters, and identify behaviors that distinguish the protein interaction environments of drug targets from the general interactome.
High-Specificity Targeted Functional Profiling in Microbial Communities with ShortBRED
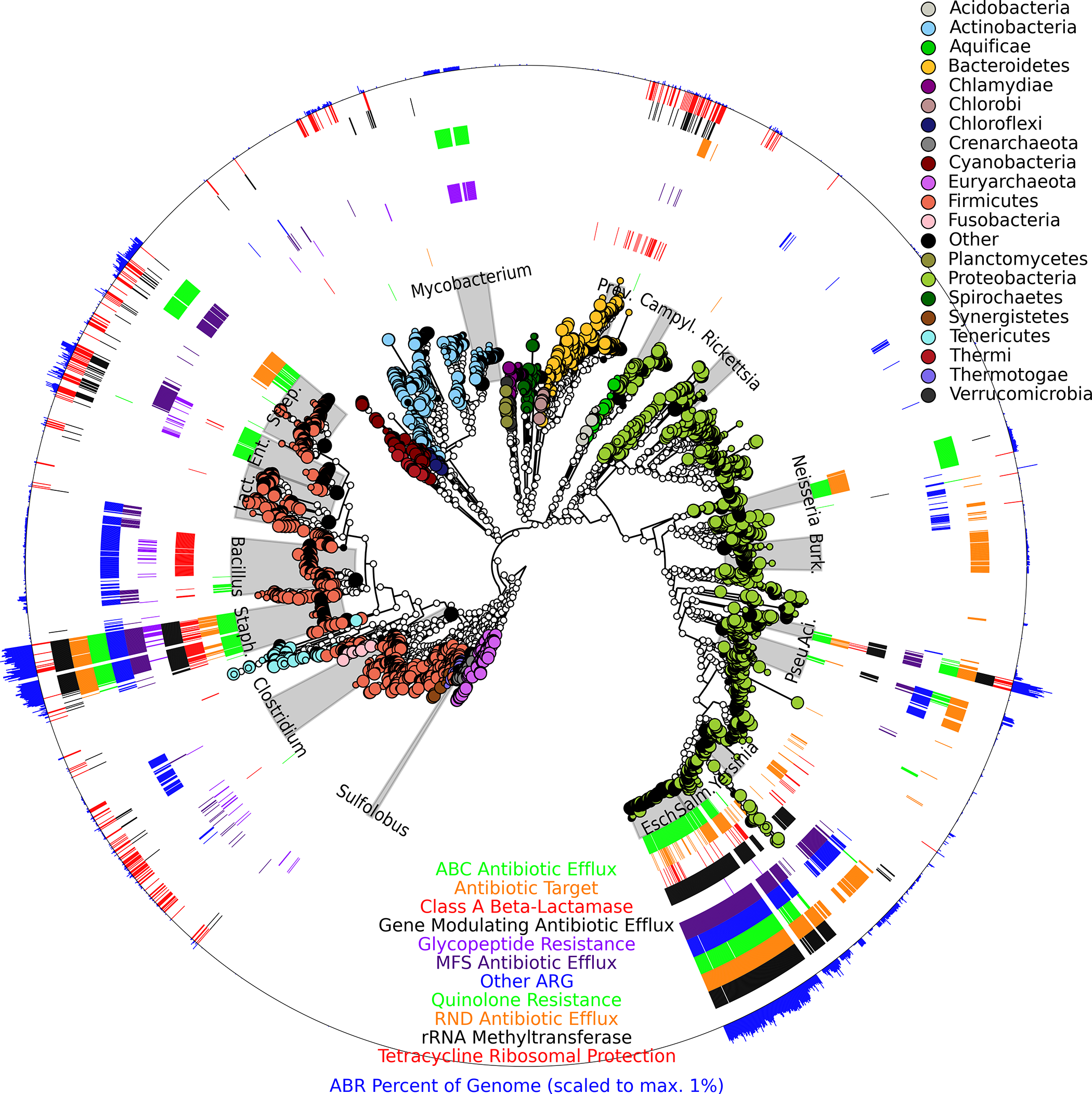
Profiling microbial community function from metagenomic sequencing data remains a computationally challenging problem. Mapping the millions of resulting DNA reads to reference protein databases requires long run-times, and short read-lengths can result in spurious hits to unrelated proteins. Curtis Huttenhower and colleagues present ShortBRED (Short, Better Representative Extract Dataset) – a method for profiling protein family abundance in metagenomic data by identifying short peptide markers that (i) are conserved within protein families and (ii) uniquely distinguish families from one another.
Featured image credit: Mitsopoulos et al.